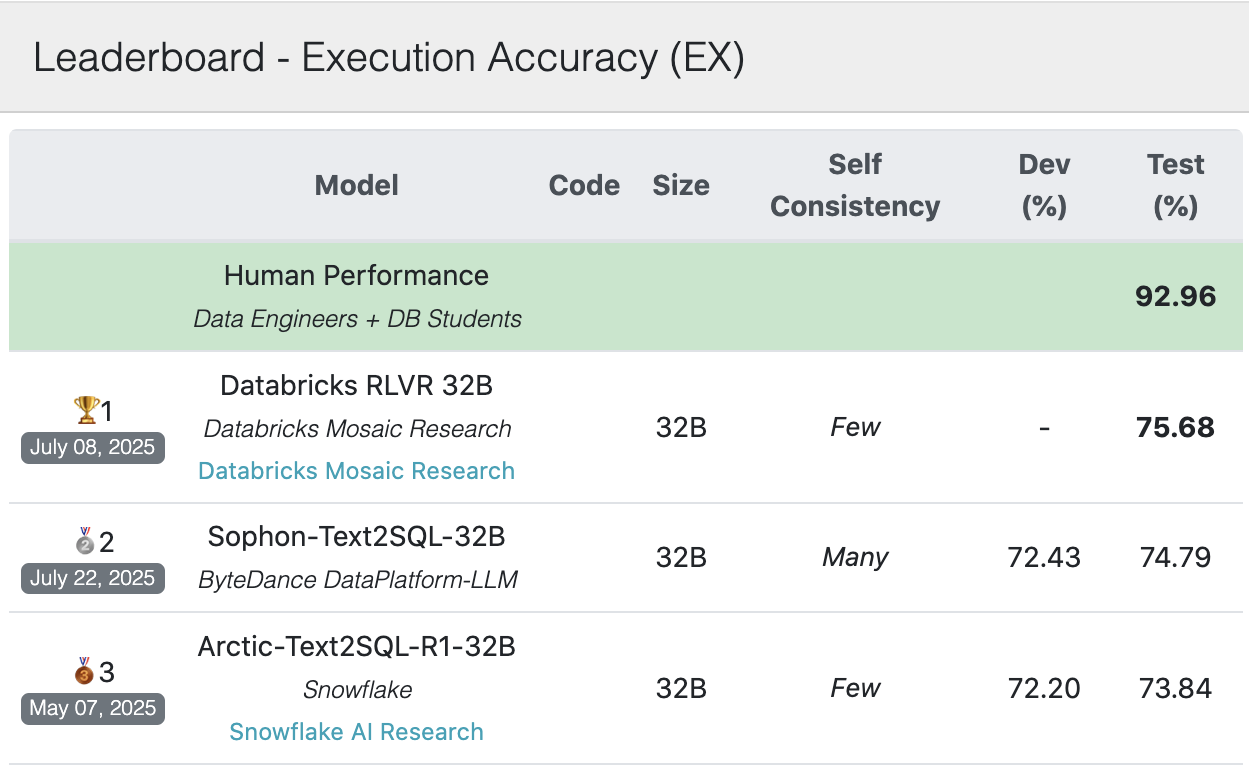
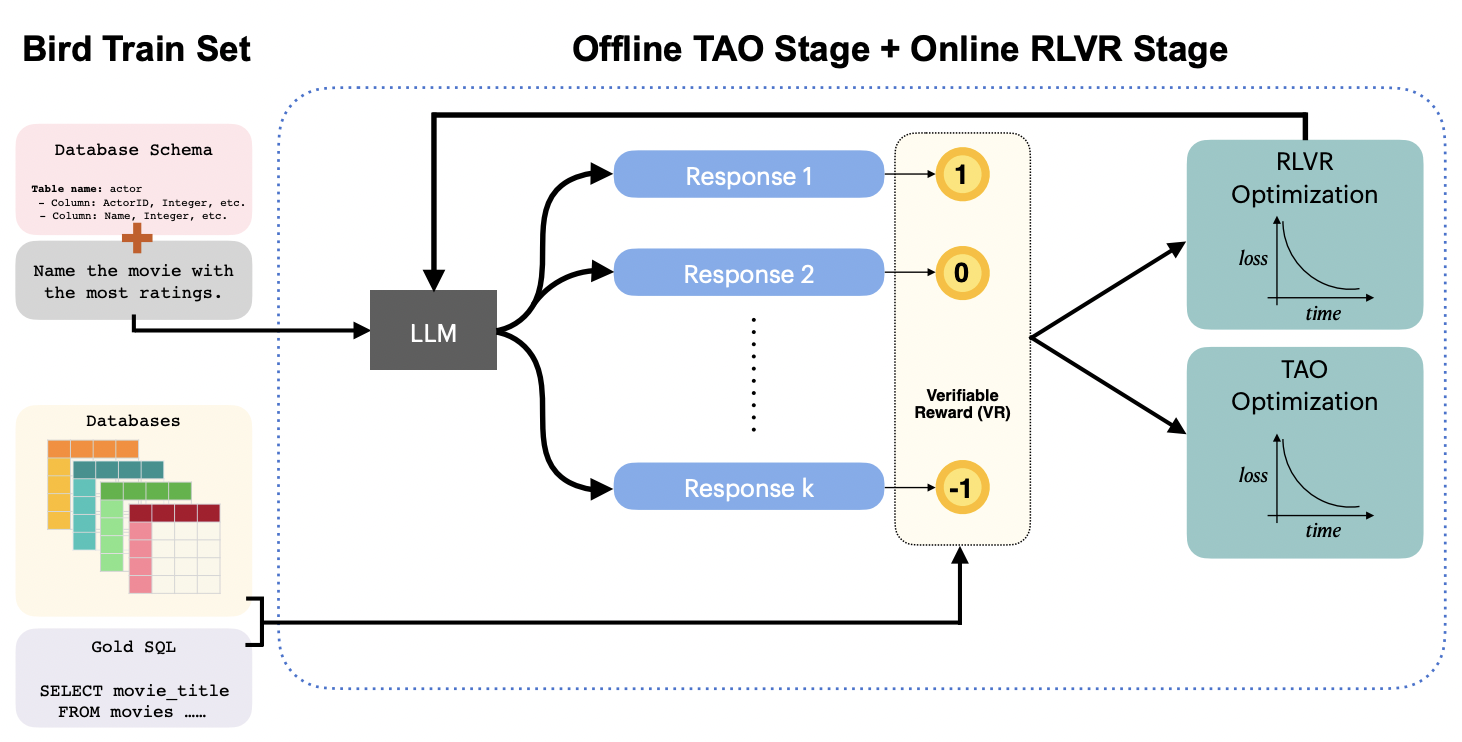
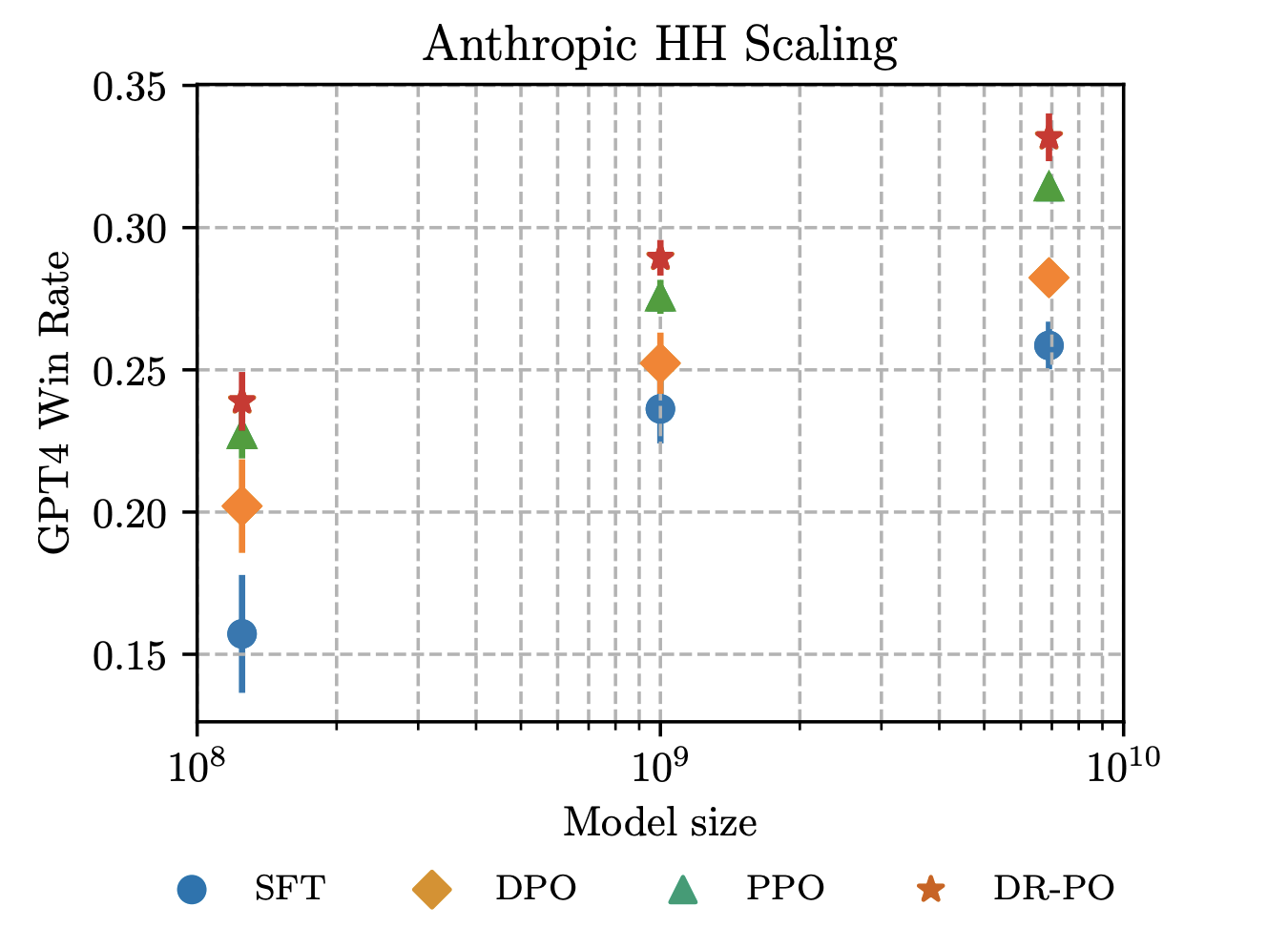
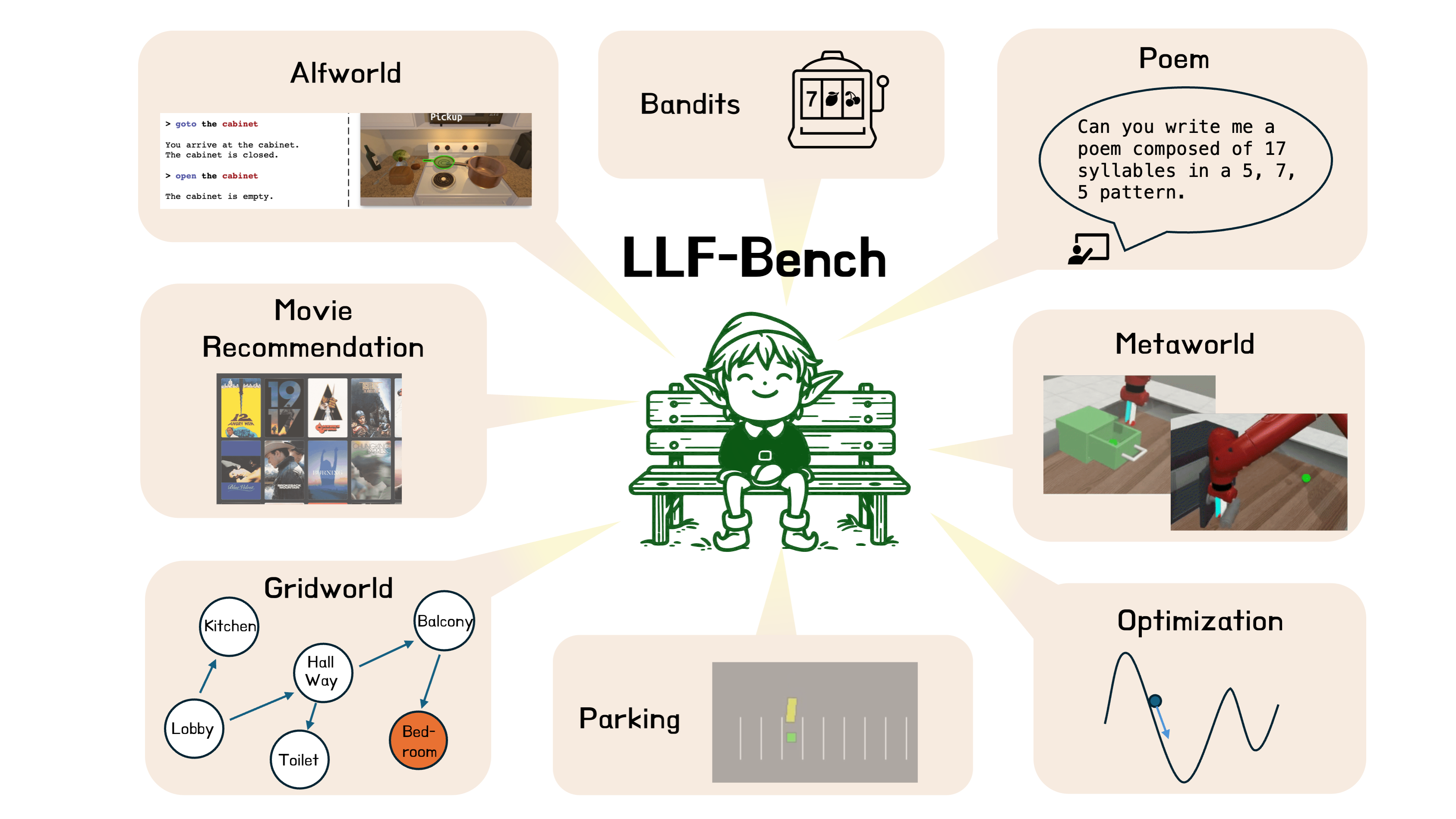
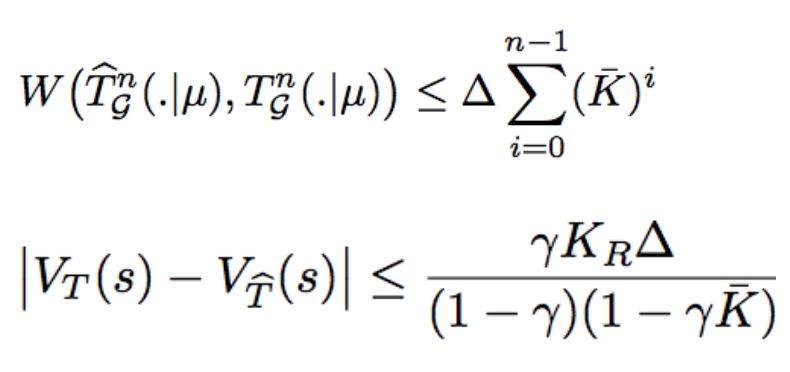Senior Researcher, Nvidia

- Senior Area Chair, EMNLP 2026
- Senior Area Chair, ACL ARR 2026
- Area Chair, COLM 2026
- Area Chair, ICML 2026
- Area Chair, ICLR 2026
- Senior Area Chair, ACL 2025
Dipendra Misra
I am a Senior Research Scientist at NVIDIA, where I work on developing Nemotron, an open-source frontier LLM. My research focuses on reinforcement learning, natural language understanding, and representation learning.
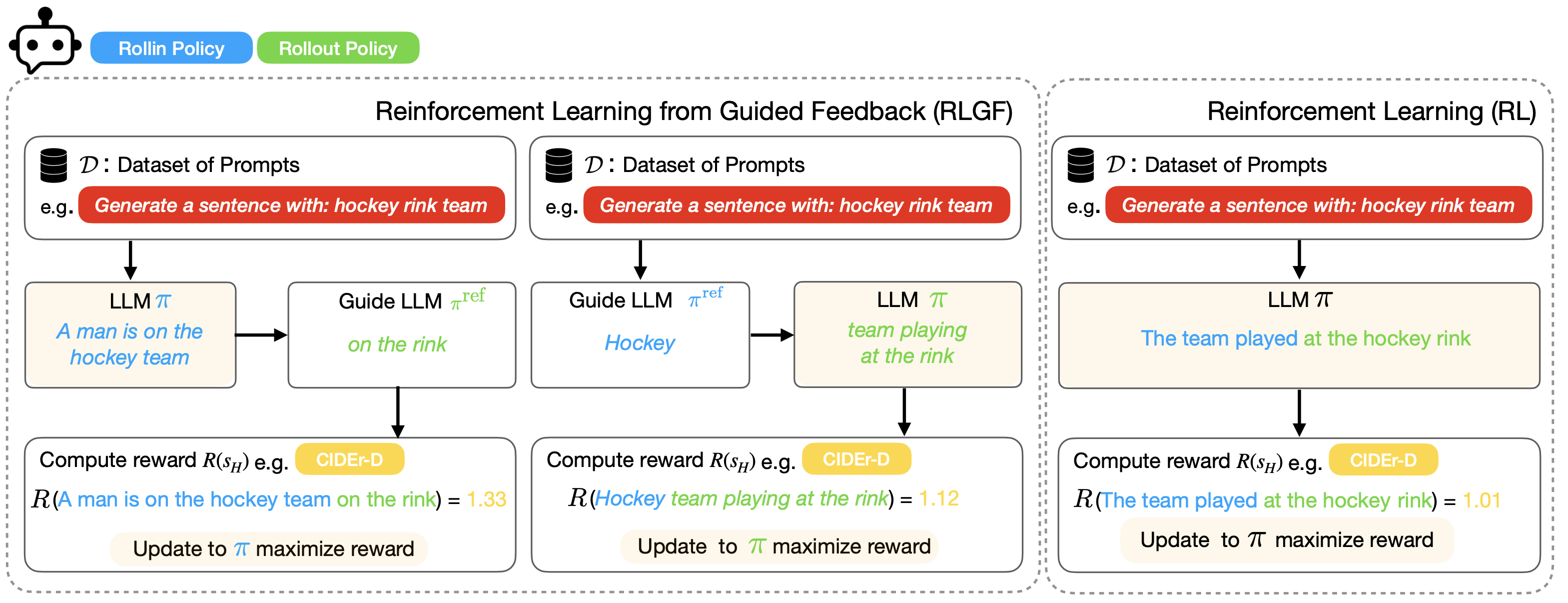
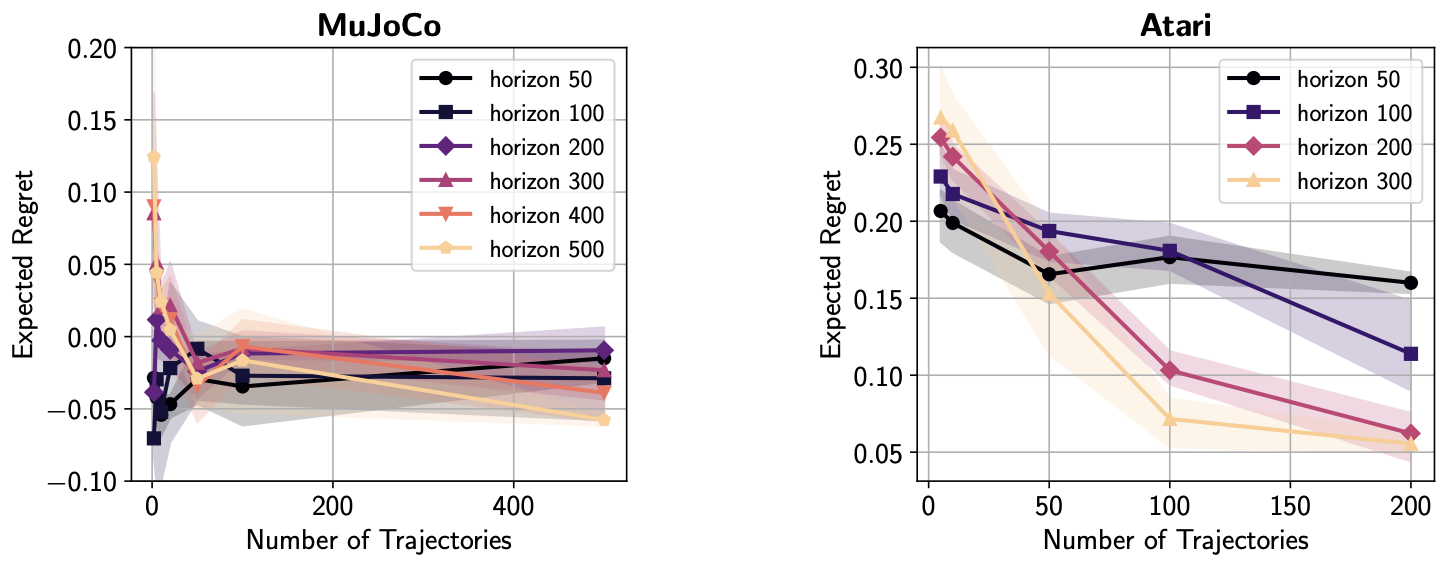
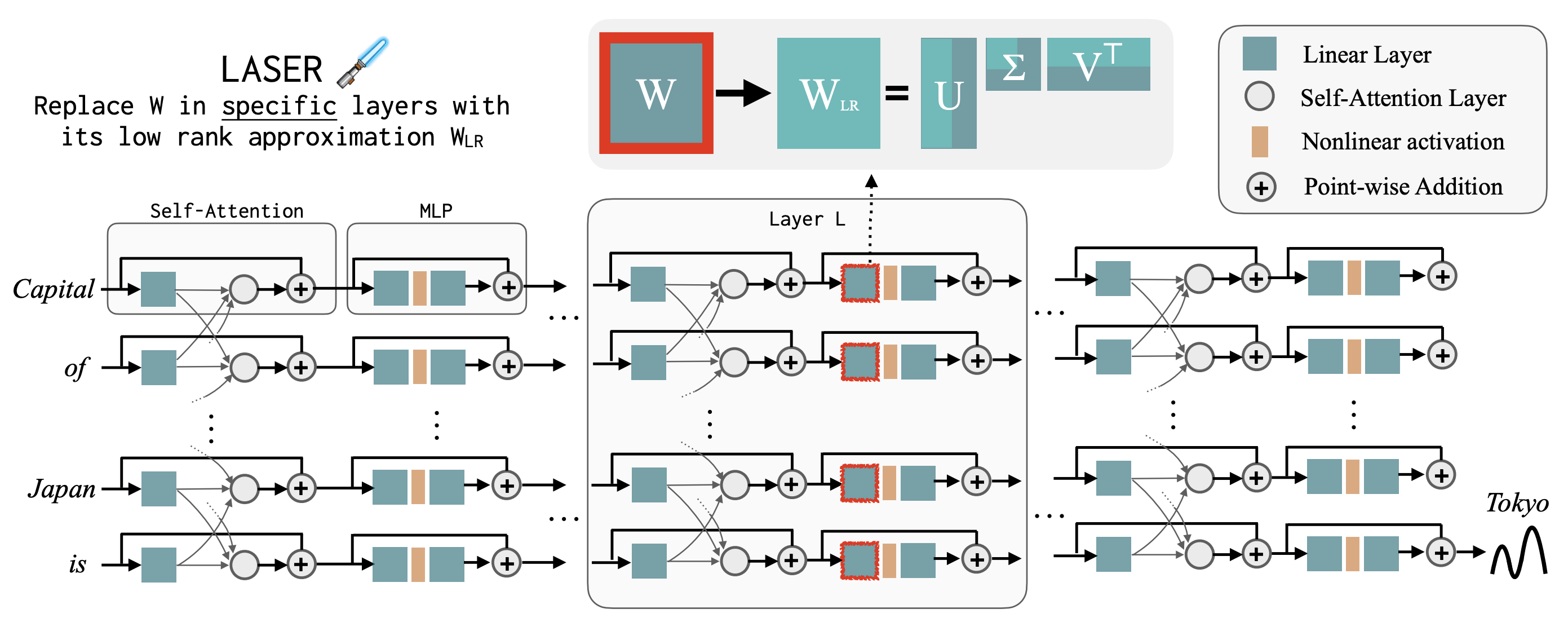
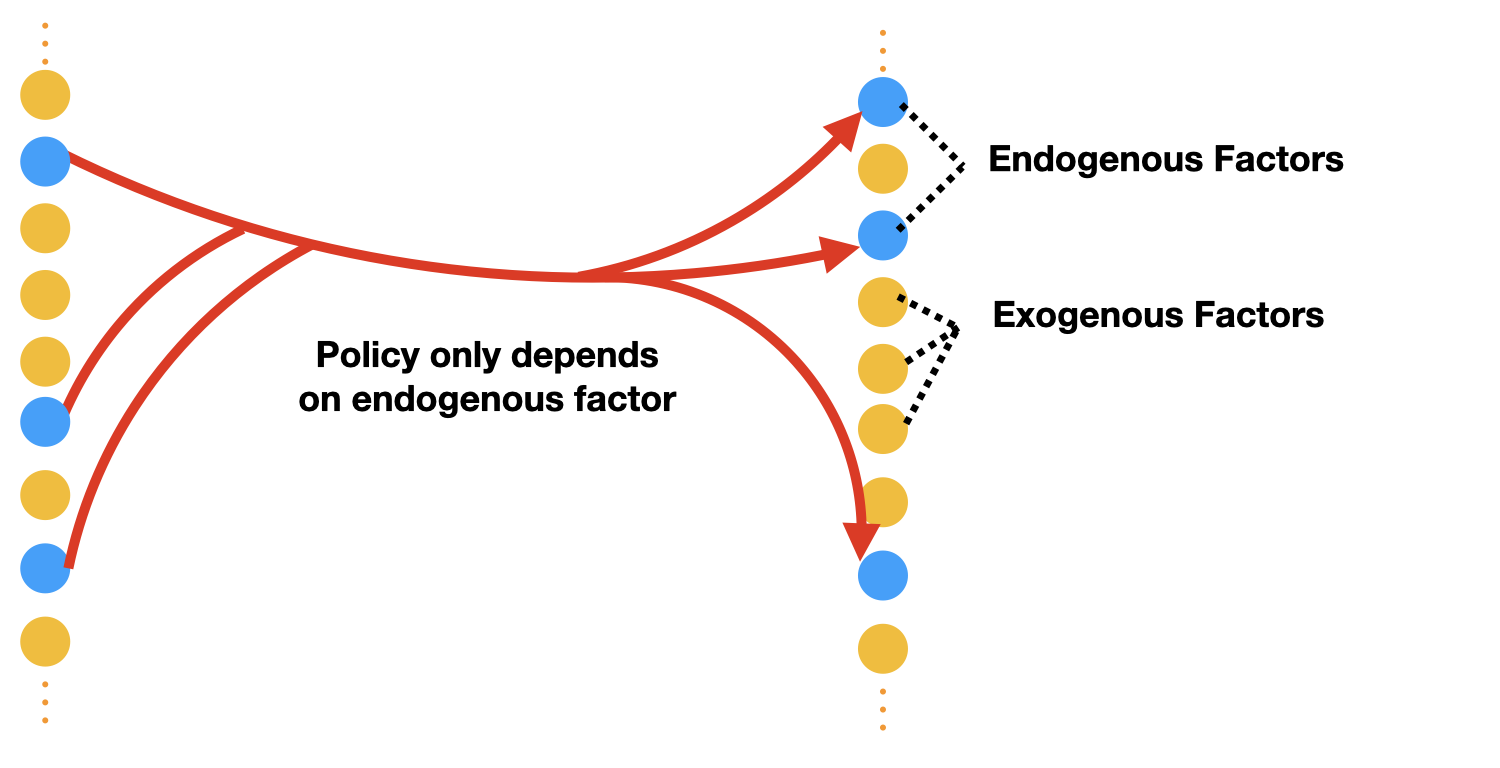
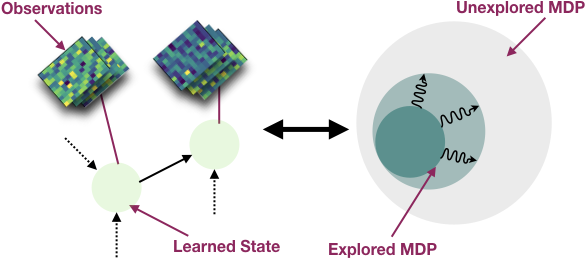
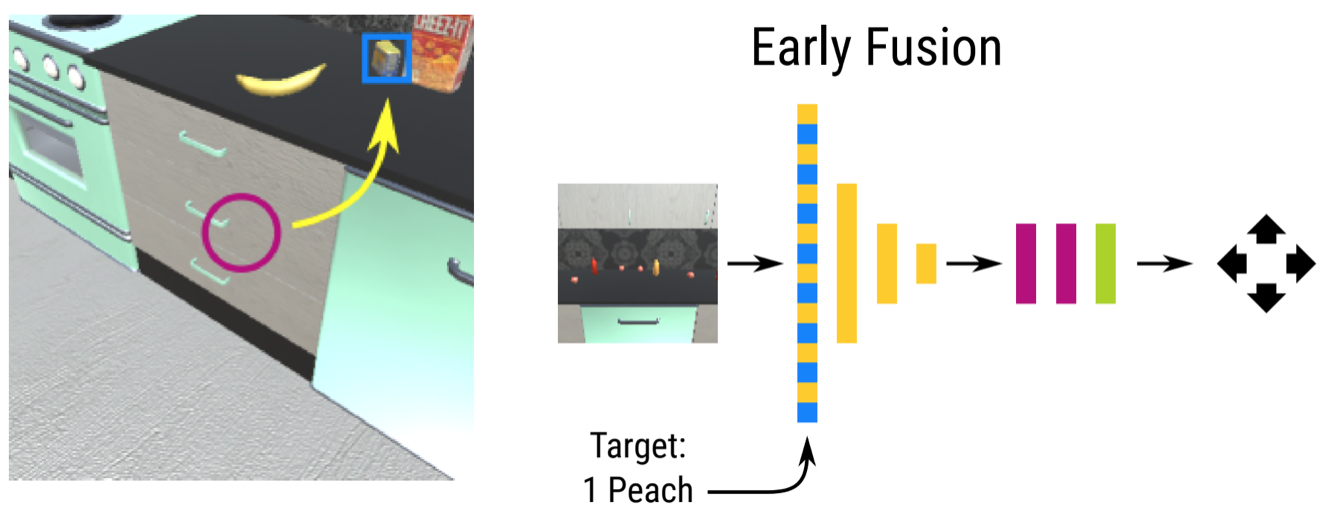
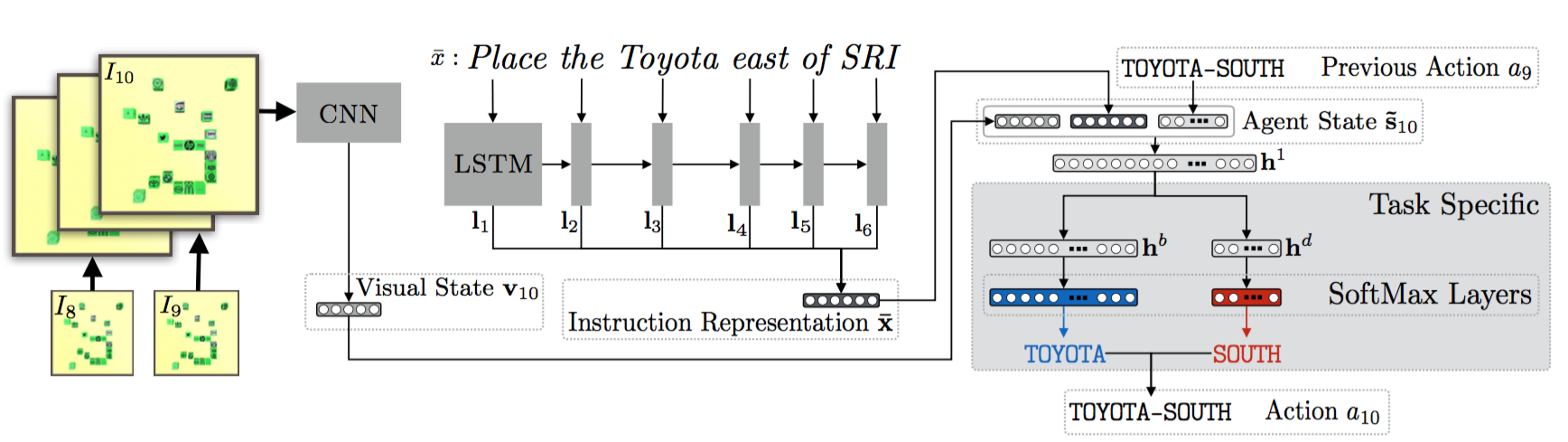
I am working on two related research problems: -- developing agentic RL methods for compound AI systems with tools, retrieval, user-feedback, etc.; and its application to
real-world tasks such as data science agents, business analysts agents, and even AI research itself.
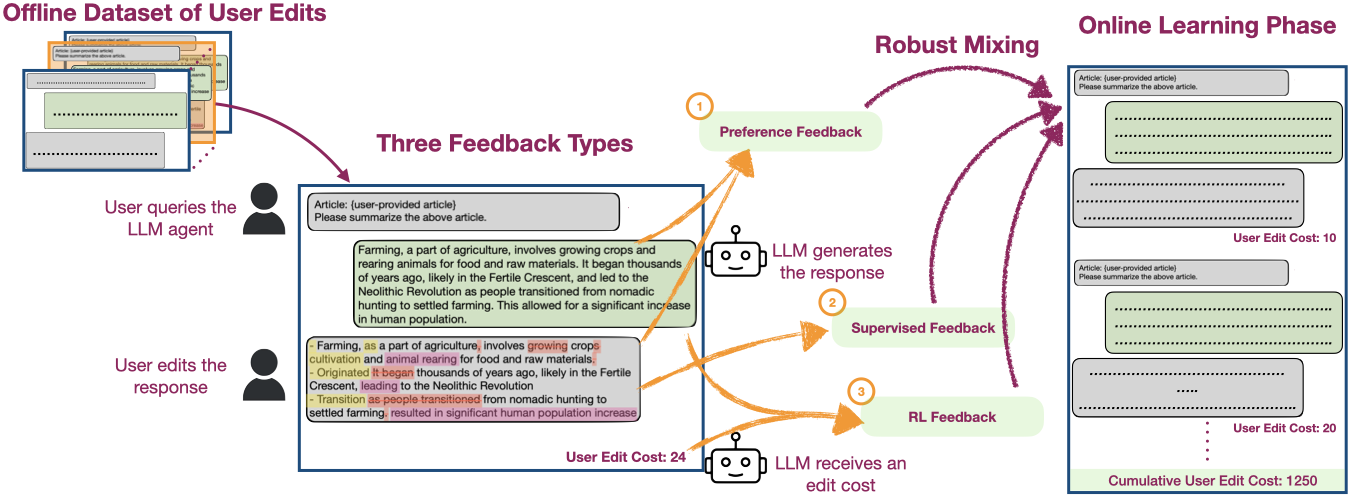
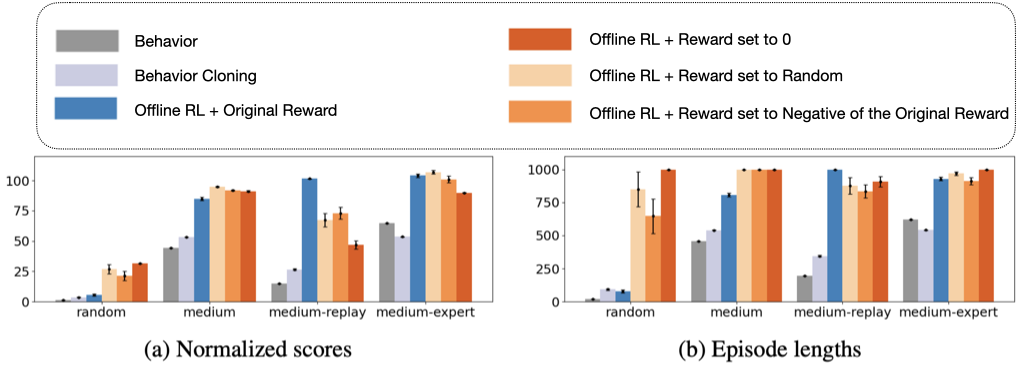
I am particularly interested in using organically-generated deployment data to do agentic RL (e.g., using user-edits, user's language feedback).
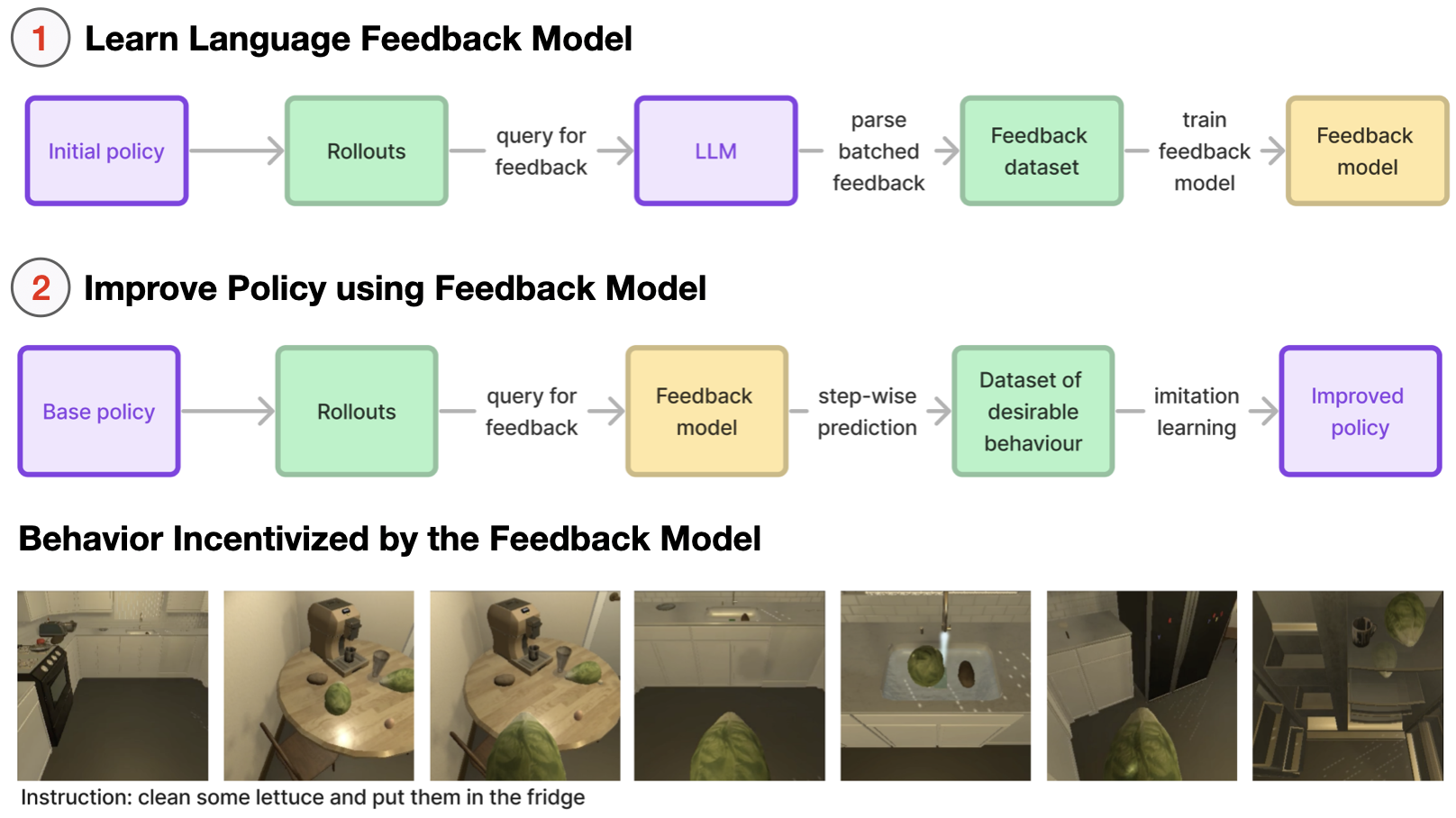
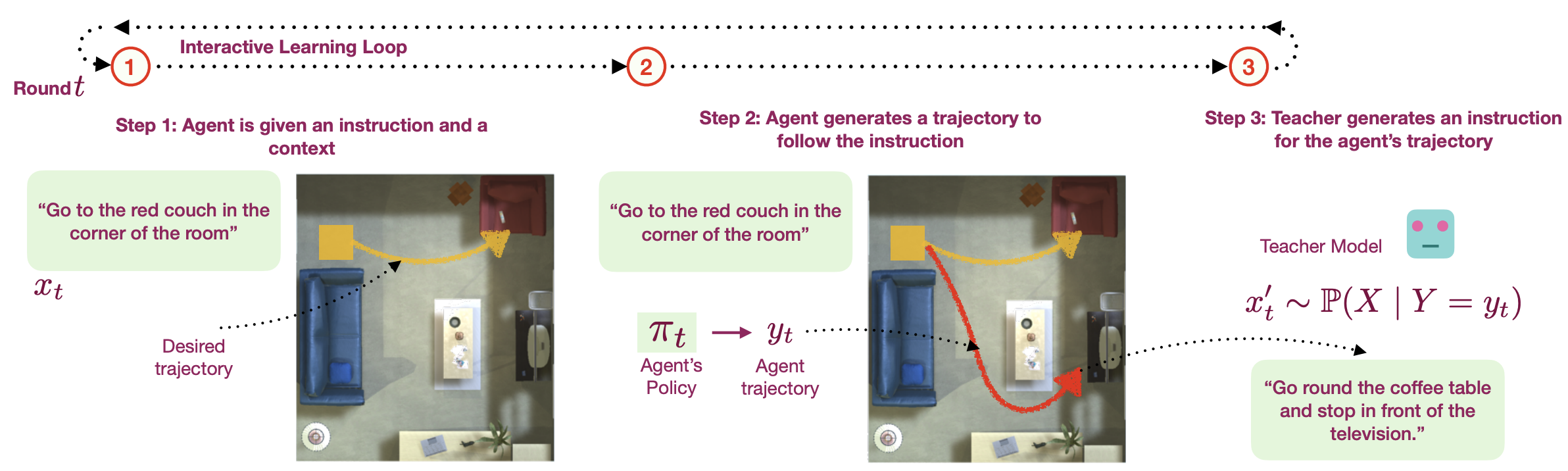
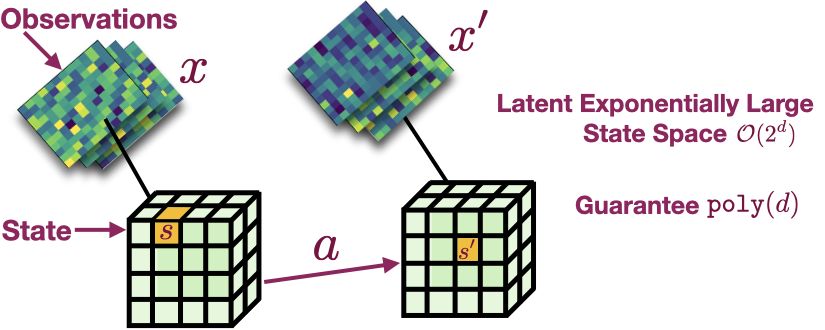
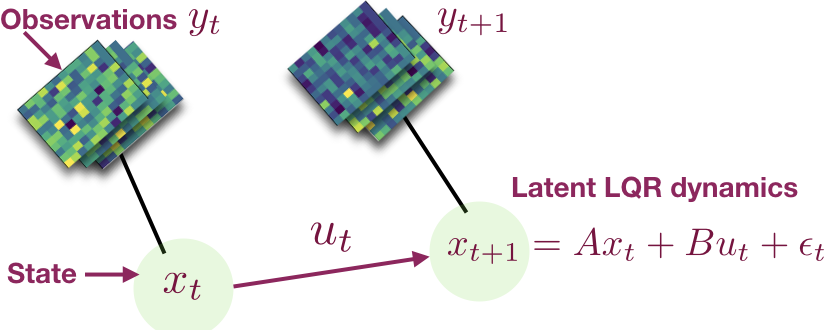
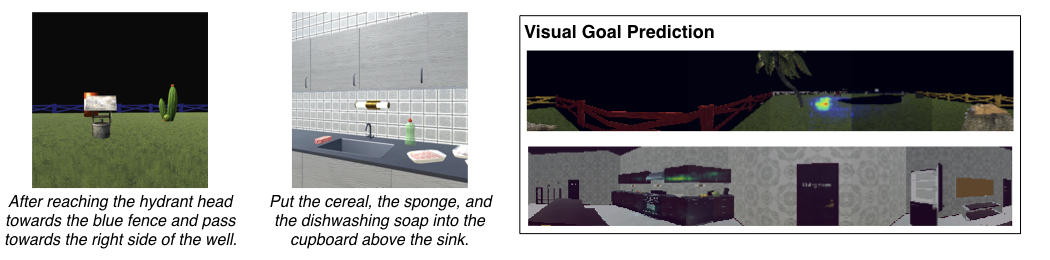
A recurring theme in my research is developing interactive learning algorithms or
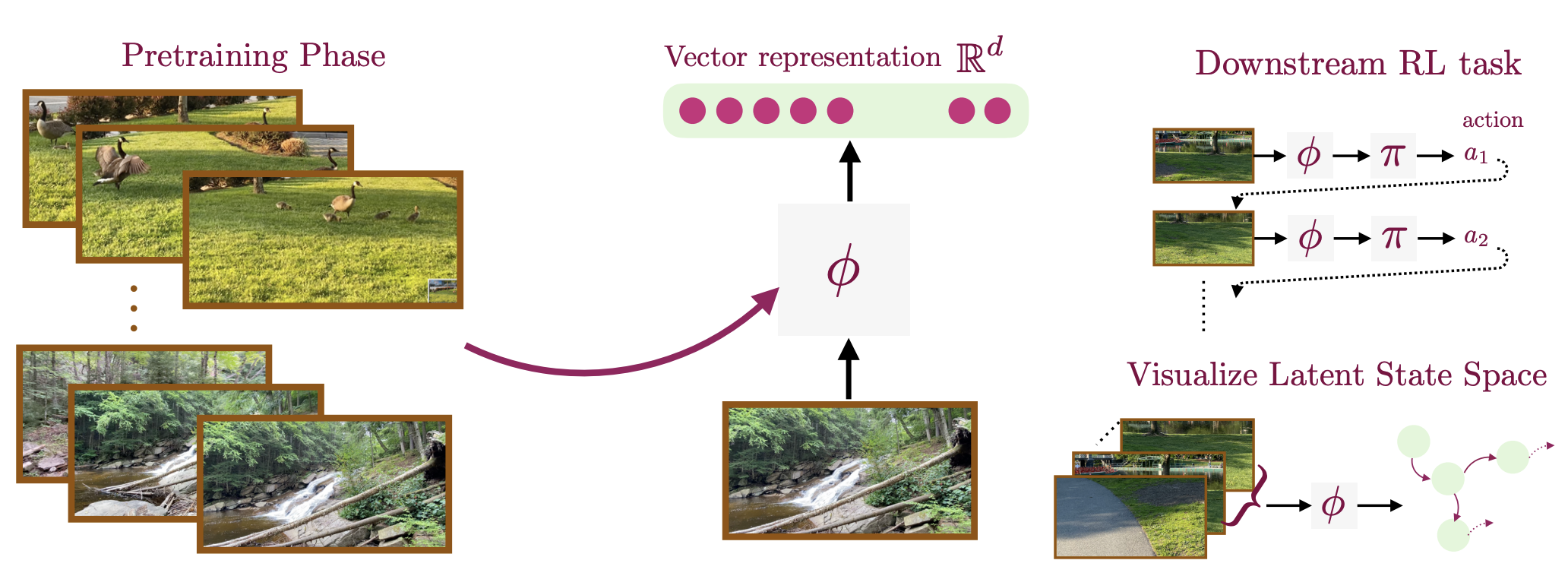
representation learning methods using feedback or data that naturally occurs in real-world such as video data, user edits, language feedback, etc.
Bio: I am a Senior Research Scientist (IC5) on the Nemotron team at NVIDIA Applied Research. I received my PhD in Computer Science from Cornell University (2019). Following my PhD, I spent time at Microsoft Research pursuing fundamental research, followed by an equally rewarding stint at Databricks Research bringing those ideas to production. At NVIDIA, I focus on a mixture of fundamental research and its practical applications to training open-source frontier models.
I am most active in the Machine Learning (ICLR, ICML, NeurIPS) and NLP (ACL, EMNLP, CoNLL) research communities. I have served as a Senior Area Chair for ACL and EMNLP, and as an Area Chair for ICML, ICLR, COLM, and CoNLL.
Quick Links: Nvidia Nemotron, Intrepid Code Base, CIFF Code Base, Math for AI, My Blog, RL Formulas