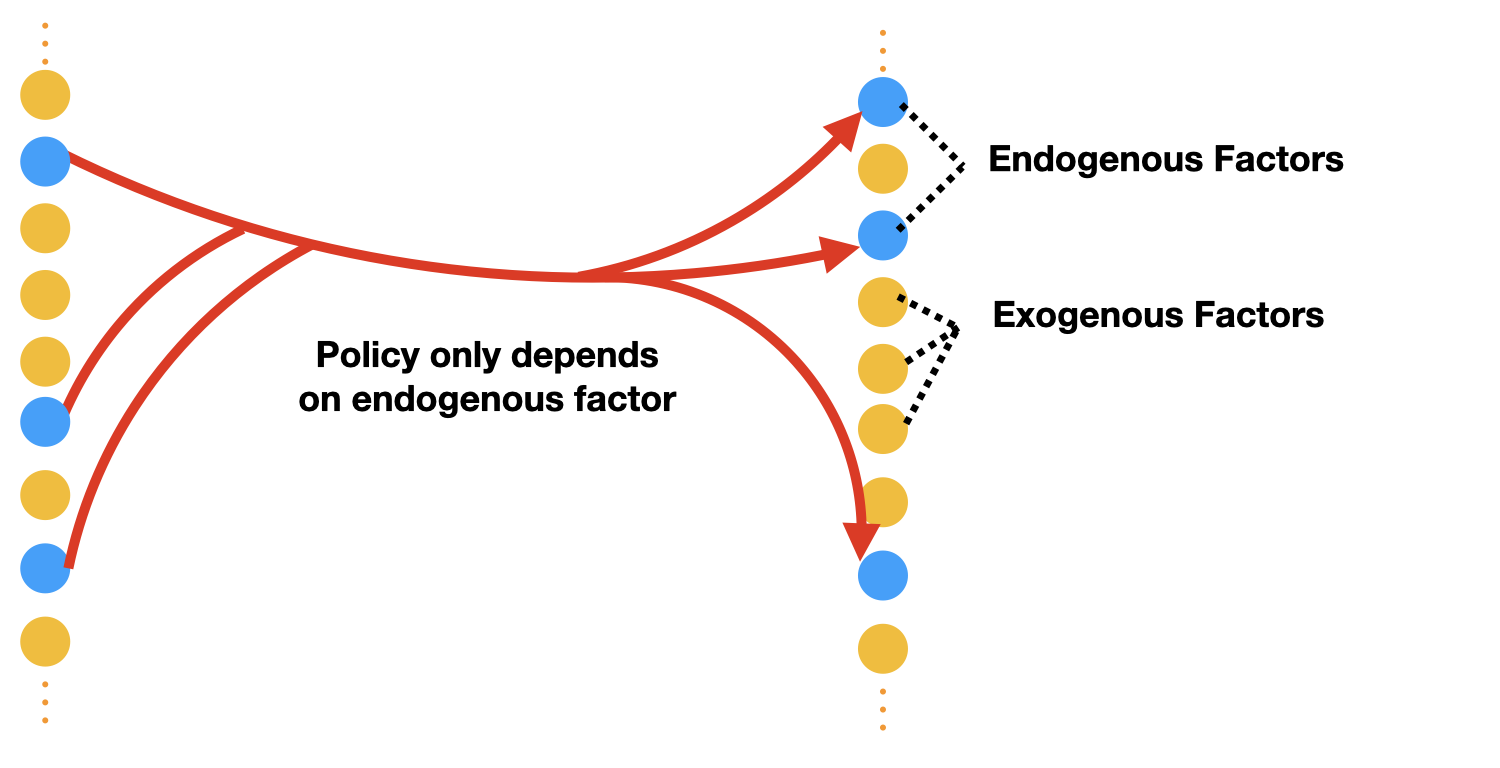
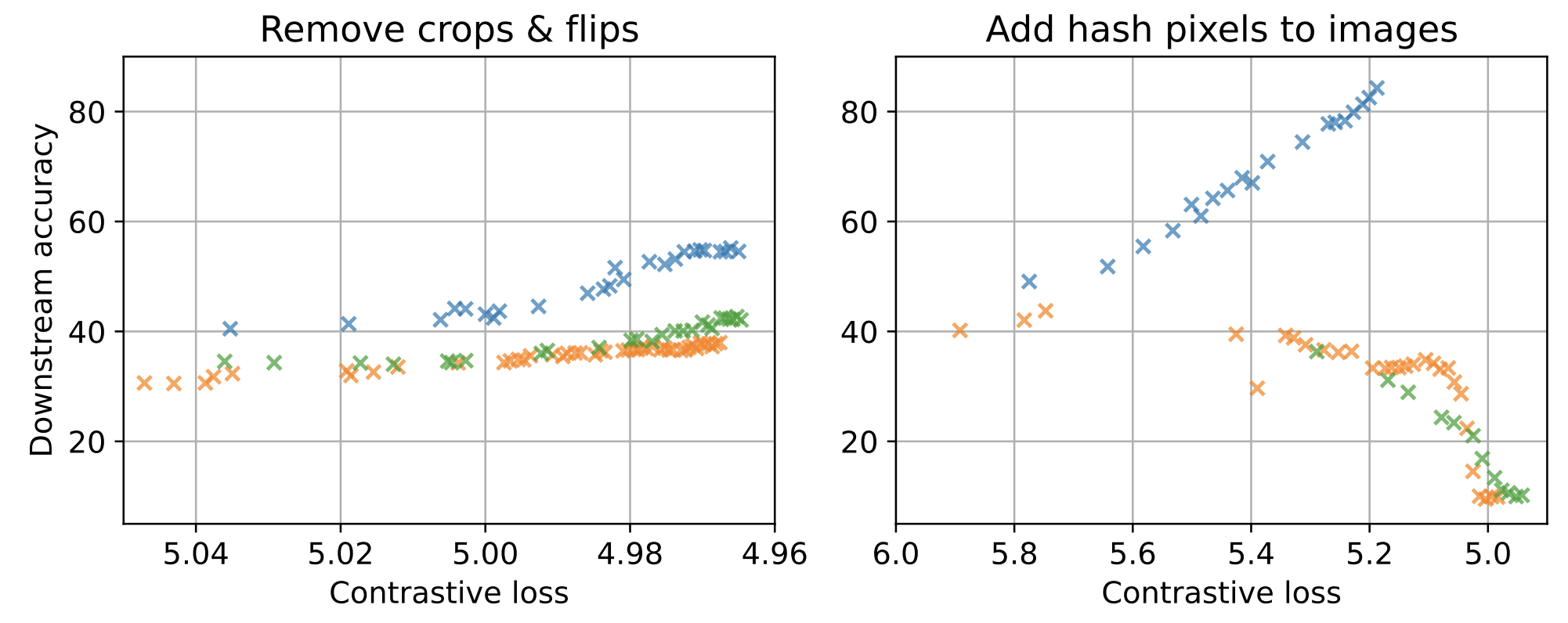
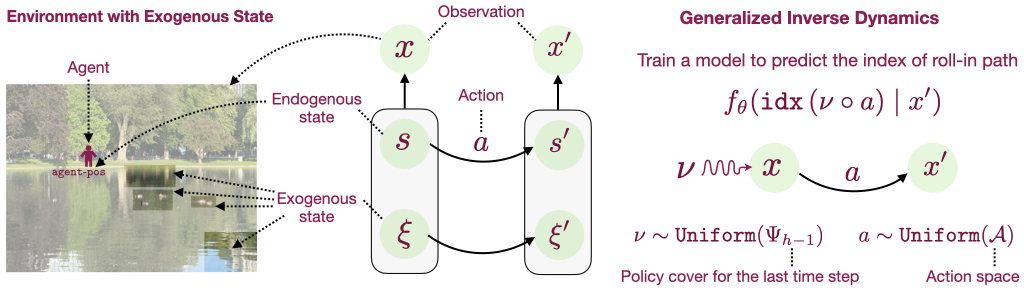
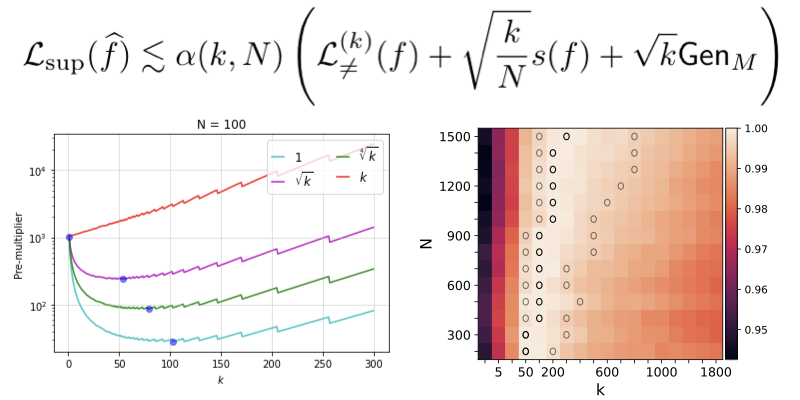
Staff Research Scientist,
Mosaic Research, Databricks

- Senior Area Chair, EMNLP 2026
- Senior Area Chair, ACL ARR 2026
- Area Chair, COLM 2026
- Area Chair, ICML 2026
- Area Chair, ICLR 2026
- Senior Area Chair, ACL 2025
Dipendra Misra
I am a machine learning researcher specializing in the field of
reinforcement learning, natural language understanding, and representation learning.
I am working on two related research problems: -- developing agentic RL methods for compound AI systems with tools, retrieval, user-feedback, etc.; and its application to
real-world tasks such as data science agents, business analysts agents, and even AI research itself.
I am particularly interested in using organically-generated deployment data to do agentic RL (e.g., using user-edits, user's language feedback).
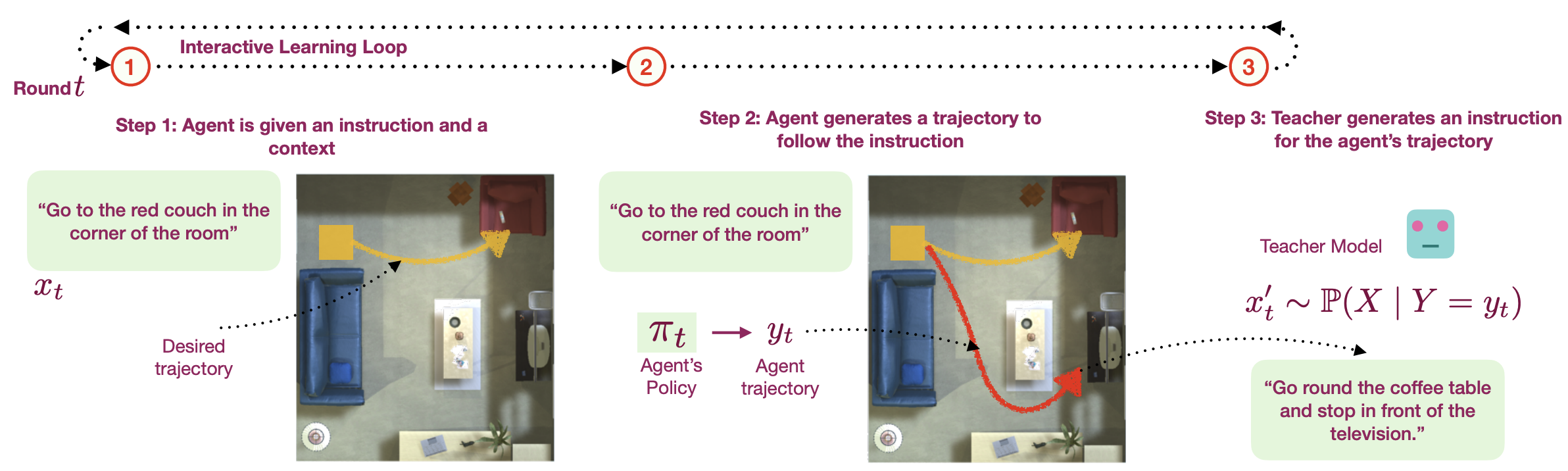
A recurring theme in my research is developing interactive learning algorithms or
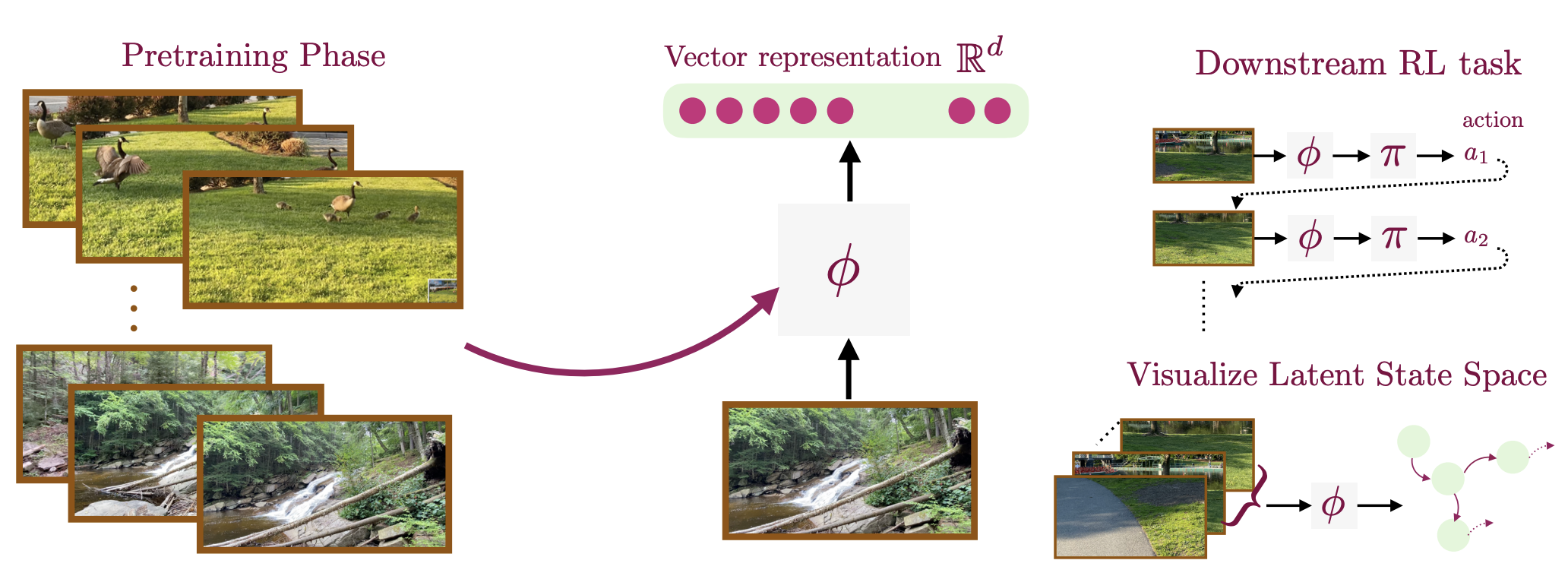
representation learning methods using feedback or data that naturally occurs in real-world such as video data, user edits, language feedback, etc.
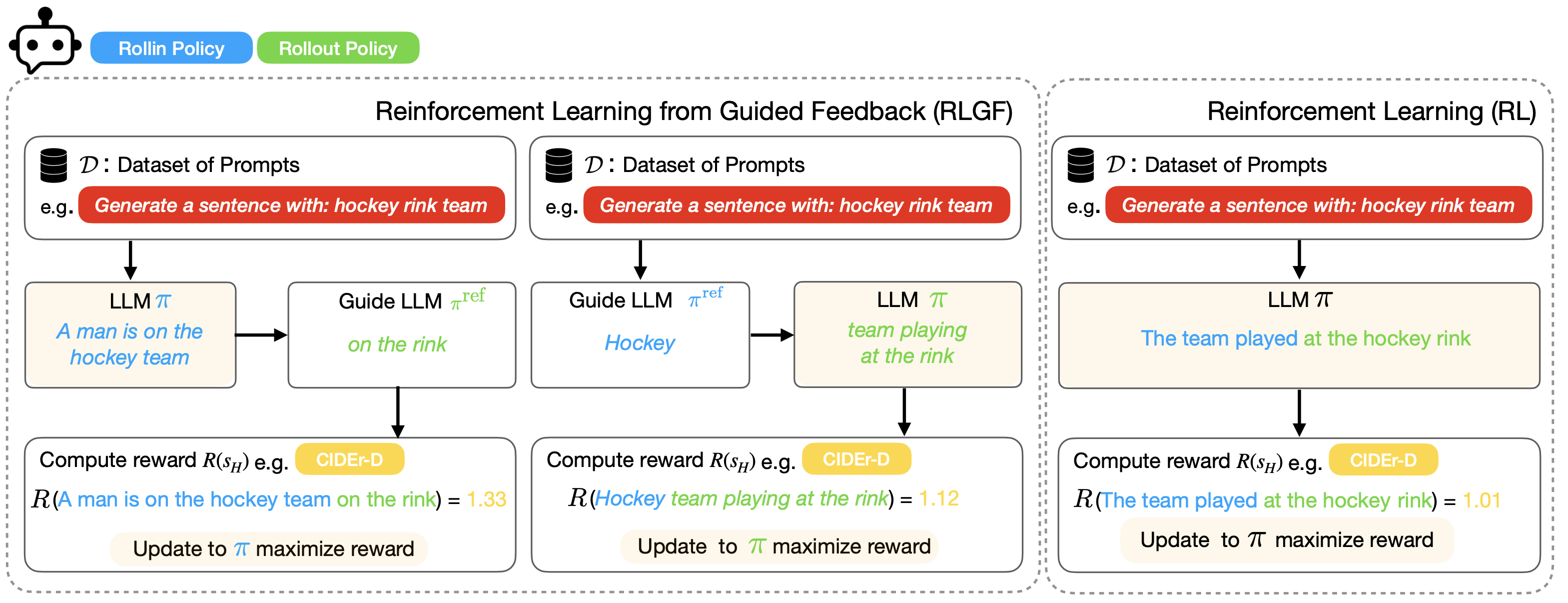
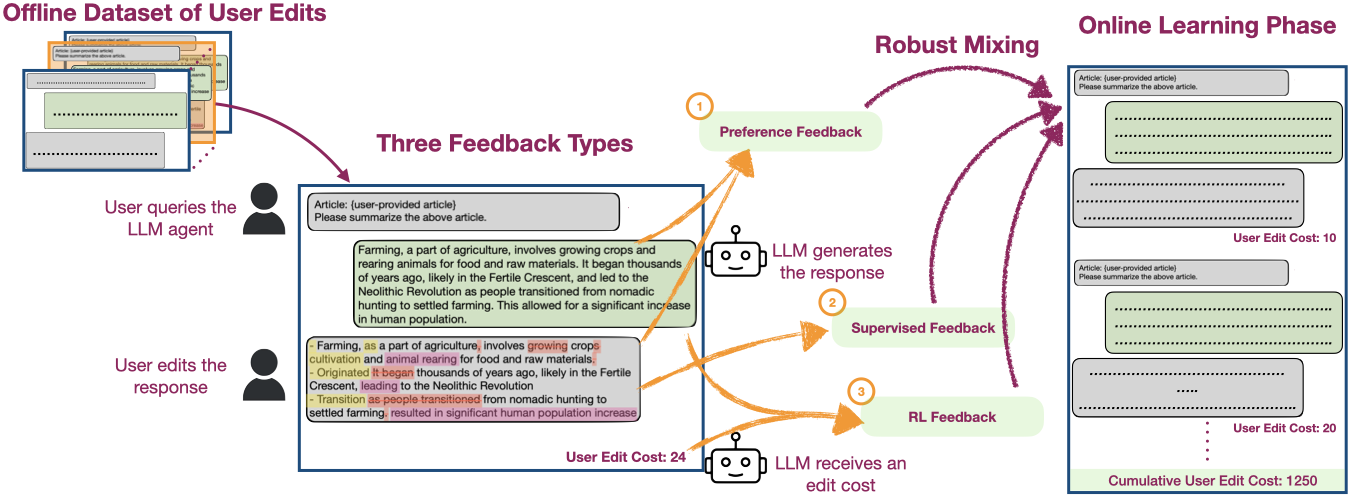
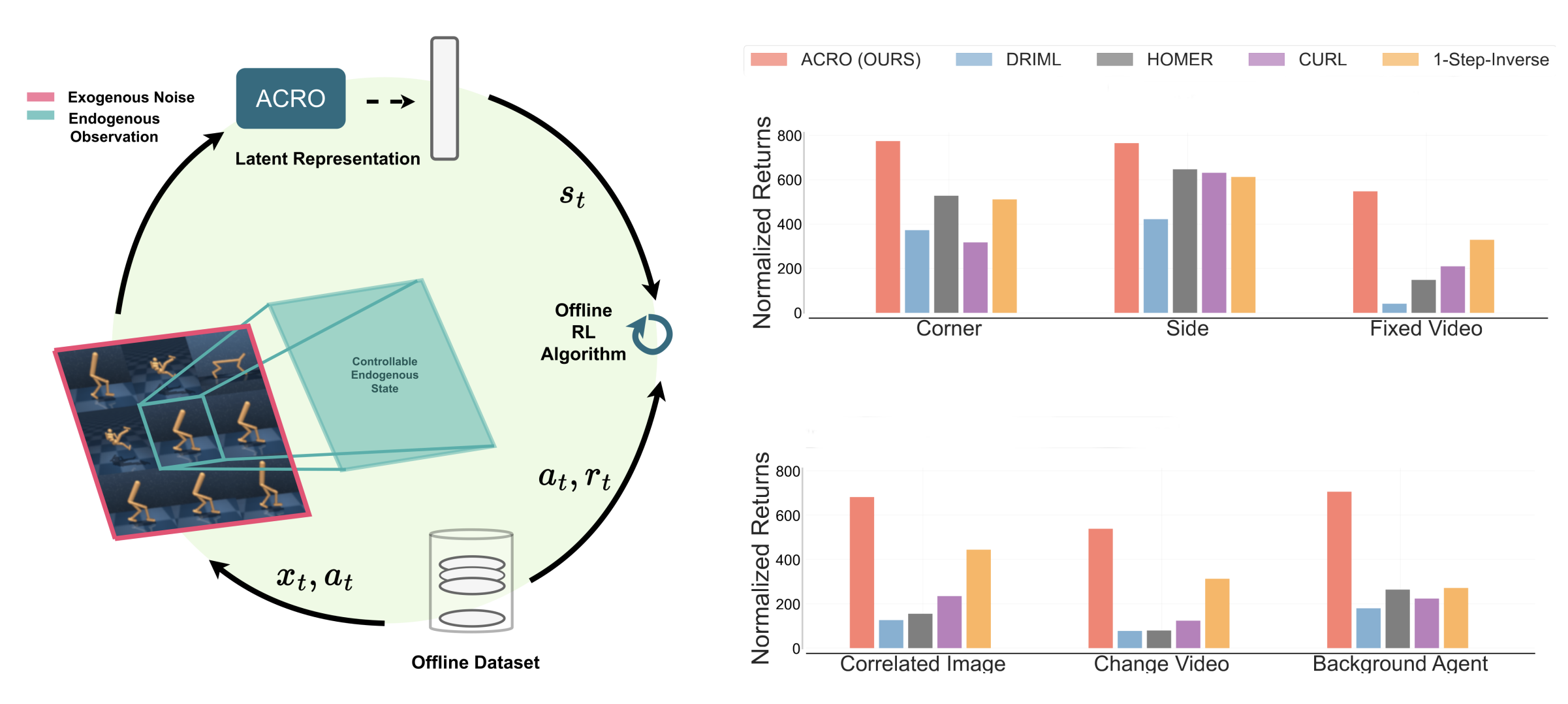
News Learning from User Edits (Jan-26-2026): Our NeurIPS 2025 paper on fine-tuning LLMs using user-edits is now on arXiv. User edits are organically generated in applications such as coding and writing assistants, making them suitable for continual learning. See all works on this topic below:
- An Agentic approach: Our NeurIPS'24 paper describes an agentic approach to learning from user edits.
- A fine-tuning approach: Our NeurIPS'25 paper describes a fine-tuning approach to learn from user edits.
- An Enterprise Application: This Databricks blog discusses how we improve coding models using user edits.
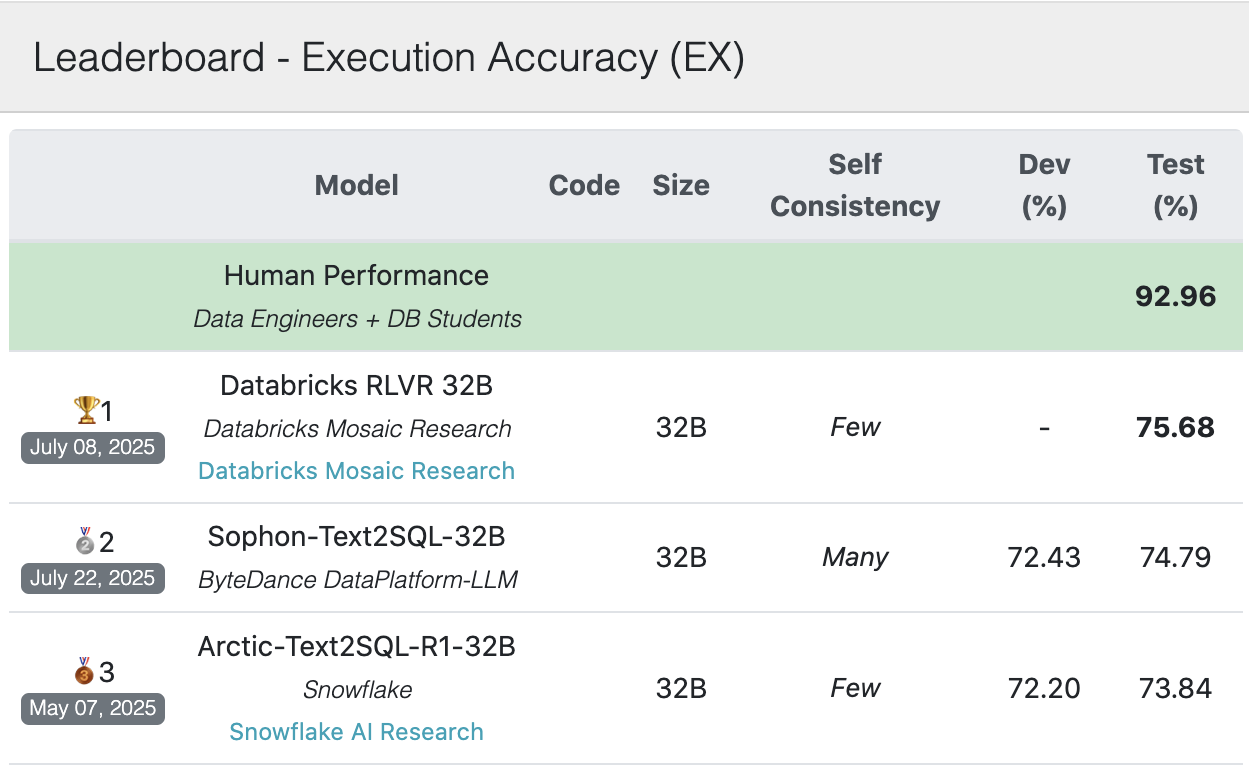
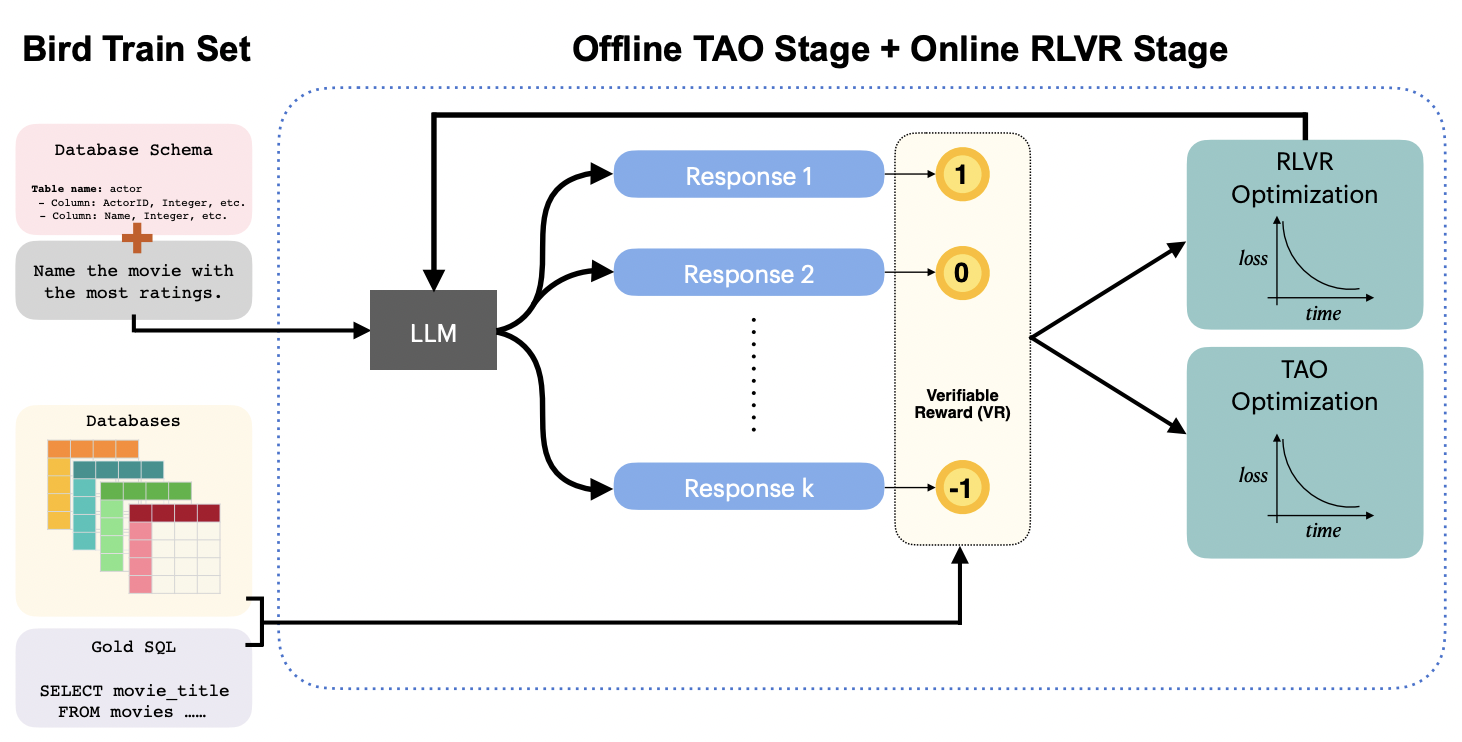
News (Aug-5-2025): Our team achieved the best single-model result of 75.68% on the popular Bird Bench with our first submission. We achieved this using our powerful RLVR recipe to train a reasoning model. Databricks customers are already using our RL recipes!
Bio: I am currently a Staff Research Scientist at the Mosaic Research team at Databricks. I received my PhD in computer science from Cornell University (2019). Previously, I was a Senior Researcher at Microsoft Research (2019- Aug 2014). I most closely associate with the ML (ICLR, ICML, NeurIPS) and NLP (ACL, EMNL, CoNLL) research communities. I have been Senior Area Chair for ACL ARR, and Area Chair for ICML, ICLR, COLM and CoNLL conferences.
Quick Links: Databricks Mosaic Research, Intrepid Code Base, CIFF Code Base, Math for AI, My Blog, RL Formulas